I’m currently doing my master’s in Financial Economics, and because I decided to do it in 1.5 years instead of 2, some semesters hammer my mind with a staggering amount of coursework. That, along with working full-time, can sometimes feel like drowning inside a vortex in the Mariana Trench.
So to ease my life a bit, after lectures I try to focus on two things: active recall of the material, and preparing for exams. One night, while reading yet another 70-page summary of why a DSGE model (something from macroeconomics) is a good way for a central bank to track shocks to the economy, I had a thought. Tired of it, I wondered: maybe I could leverage AI to accelerate my studying and sharpen my understanding along the way.
So I spawned a terminal with Claude and started feeding it. Naturally, I began with the syllabus. Then down the rabbit hole I went, I threw in my homework, my answers, lecture slides, Zoom annotations, even previous tests.
It turned out Claude really loves building interactive classes, and we started going back and forth on what to add and how to make it interactive. The results were nothing short of amazing. It built a full UI with the lectures numbered, and in each one it added ELI5 sections for every topic, exercises and quizzes tied to the exams for practicing new material, even lecturer notes on points that mattered which I’d forgotten were ever there.
After doing this for every class and seeing sharp results(in my grades) and more importantly in my understanding, my appetite only grew.
I’m in the habit of really understanding what interests me. A while back, when I started learning computer science and cyber, I used to read really, really long books 1000+ pages sometimes. From experience, if you summarize those books down to about 250 pages (roughly a 1:4 ratio) you get 90-95% of the value; in 150–200 pages you might get 70–80% ( I’m eyeballing these numbers).
There are exceptions, of course, learning an OS, say, where if you don’t know the small caveats of every corner you might land at a rounded 0%, but for most subjects, especially math books, that ratio holds up.
So I started brewing on how to transform my huge, overgrown reading list into the same kind of interactive class. Then it happened: DeepSeek released their V4 models, with prices so cheap I think they might bill me more after reading this.
Then I did what I do best, I went looking for useless academic papers explaining how someone had already done exactly what I wanted to do, months before me, because I’m a slow snail. And yep, these folks (kudos for the paper, it’s great and informative) did exactly what I set out to do, only on a small set of books, and it cost them a lot more because at the time LLMs were dumber and more expensive for this kind of task (huge-context chats).
So here’s how my framework actully works:
The naive approach, paste a whole 700-page PDF into a chat and ask for a summary, is exactly what made the earlier attempts expensive and unreliable. Long context is costly, and the model loses the plot in the middle. So I built a pipeline instead.
The core idea is a trailing window. For each chapter, the model only ever sees three things:
The chapter’s entry from the table of contents - so it knows the scope and the author’s intended boundaries.
A compressed summary of the previous chapter - just enough continuity so notation and running examples carry forward.
The chapter itself, cut out from the rest of the book (extracted with pdftotext -layout and page-mapped).
That’s it. No 700-page context. Each chapter is a small, cheap, focused generation, and the trailing summary keeps the book coherent across chapter boundaries.
Thanks for reading! Subscribe for free to receive new posts and support my work.
The pipeline (I call it the content_factory) runs roughly like this:
PDF + TOC
│
├─ extract chapter text (pdftotext -layout, page-mapped)
│
├─ build trailing window: [TOC entry] + [prev-chapter summary] + [chapter text]
│
├─ DeepSeek V4 ──▶ drafts a 9-tab chapter module (HTML + cards JSON)
│
├─ QUALITY GATES (two layers)
│ ├─ deterministic: does every theorem cite a page range?
│ │ is the HTML well-formed? does the math render?
│ └─ LLM judge (cross-family): a *different* model family scores
│ source-fidelity and invention count
│
├─ INVENTION SCORE: hallucinated content is scored heavily negative.
│ The chapter must clear the gate to pass.
│
├─ ITERATIVE LOOP: fail → repair/regenerate → re-score
│ (capped iterations + a manual checkpoint)
│
└─ OUTPUT: books/<slug>/<chXX>.html (the readable module)
books/<slug>/<chXX>.js (flashcards + exercises)
books/<slug>/meta.js (chapter map, page ranges)
Now, Logically, every person with a brain working would say that LLMs are hallucinating, YEP , THEY ARE, A LOT,
The single hardest problem in this whole project is inventions, when the model confidently states a theorem the author never wrote, or “improves” notation, or invents a worked example with a wrong answer. For a study tool, a confident hallucination is worse than a gap, because you’ll memorize it.
A few things kept this under control:
Source-evidence is mandatory. Every theorem, definition, formula, and worked example has to trace back to a page range in the source. No citation, no pass.
Cross-family verification. The generator is DeepSeek; the judge is a different model family (Claude / GPT / Gemini). Same-family verification produces theatrical independence, a model is too forgiving of its own style. Cross-family scoring is harsher and catches more.
Invention is scored low in the chapter’s total score, so a chapter with drift keeps failing the quality gate and gets regenerated until the invention count drops low enough to clear it. It’s an iterative loop, not a one-shot.
Trust labels on every claim. Each piece of content is tagged: SOURCE-LOCKED (verbatim from the book), SOURCE-CLOSE (a faithful paraphrase), INFERENCE (the model’s own reasoning), UNVERIFIED, or BLOCKED. A per-chapter banner shows the overall state.
Three study modes.Strict shows only source-locked content; Learning allows source-close paraphrase; Full shows everything including inference. You choose how much you trust on any given day.
I won’t pretend it’s at zero, LLMs are non-deterministic, and chasing the last invention to zero just makes the prompts brittle and the output bland. Visual review beats invention-count obsession as a quality signal.
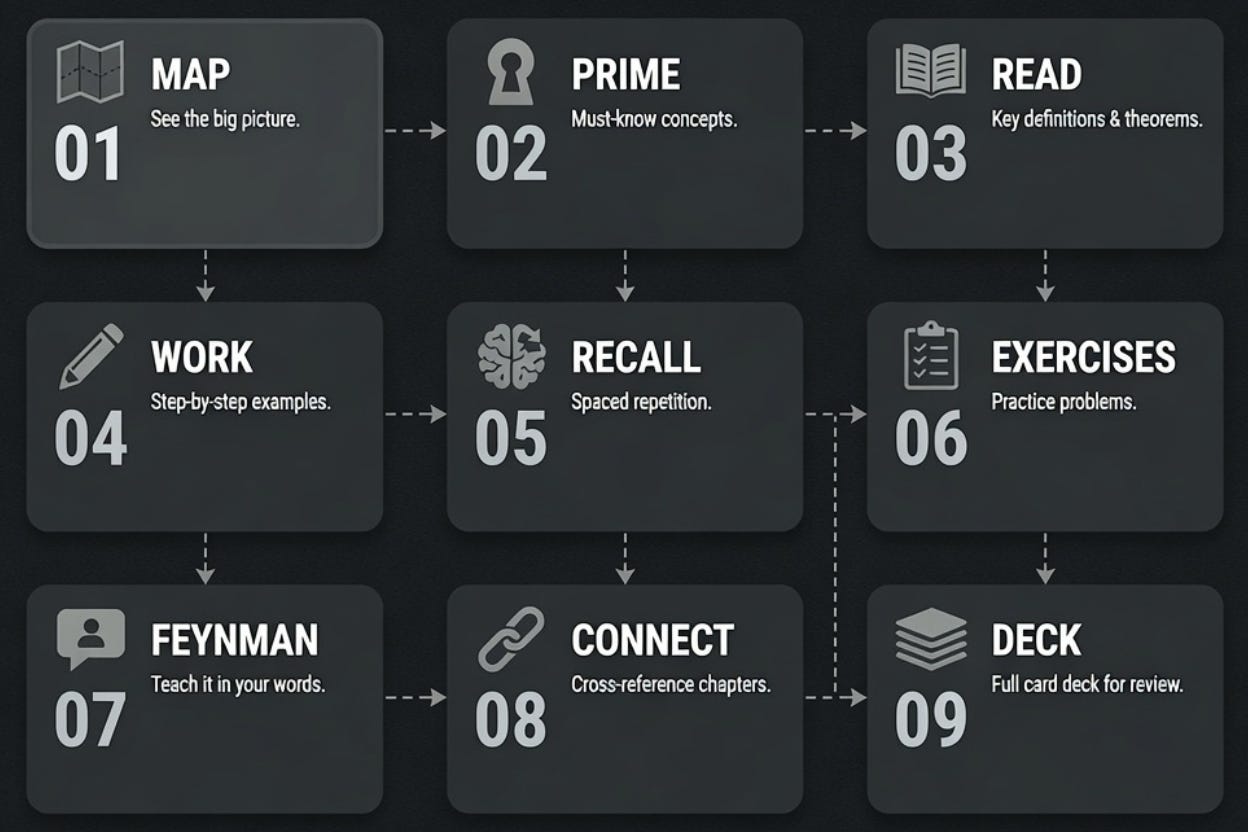
The generated content isn’t a wall of text. Each chapter is a module with nine tabs, designed around how I actually study:
Under the hood it’s a small, dependency-light engine (vanilla JS, no framework):
A spaced-repetition scheduler (SM-2-style) with six card types: cloze, basic, reverse, numeric, theorem, algorithm-step.
All state lives in localStorage under one key (books_learning.v1.state), with JSON export/import so I can move it between machines. No cloud, no account.
A daily review surface (today.html): due cards + a reading target + an activity heat map.
A cross-book Atlas: an aggregated glossary, a formula sheet, an SVG concept map of how the 49 books relate, and an interleaved-problem generator that mixes problems from across books for daily practice (interleaving is one of the most evidence-backed study techniques there is).
Here’s the part the papers don’t talk about. Generating the content is maybe 20% of the work. The other 80% is making 10,000 pages of dense mathematics actually render in a browser without looking like garbage.
PDF extraction corrupts LaTeX in a hundred small ways: a lost $ turns $2.83 of currency into broken math; a stripped newline turns \nabla into a stray abla; the model mixes \(...$...\) delimiters mid-expression; greedy $...$ matching crams a whole sentence into italic math so you read ispositvelyrelatedto.
I ended up writing a whole sanitizer layer (a pile of python passes) that restores lost currency, re-stitches broken commands, normalizes delimiters, and strips stray dollar signs, plus a MathJax v3 config with custom macros, and a final pass that hides any irreducible error markers so a reader never sees a red “math input error” box. Across ~984 chapters, the visible MathJax error count went from thousands to zero.
It’s deeply unglamorous work. It’s also the difference between a demo and something you actually want to read at 11pm.
The whole thing runs at roughly $10 a book. Set that against a private tutor doing exercises with you at $100 an hour, and it’s a bargain, even before you count that the library doesn’t get tired at 2am.
The library looks awesome, the pipeline is repeatable, and the skeleton is something I can hand to anyone else drowning in their own reading list.
Thanks for reading.
If you want the engine and the pipeline, though honestly, you could build your own, send me a message.
Thanks for reading! Subscribe for free to receive new posts and support my work.